GSS
Chen, J., Lu, J., Zhu, X., & Zhang, L. (2023). Generative Semantic Segmentation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).

概览
文章对语义分割这个问题有了重新的定义,作者把传统的语义分割方法,即解决基于判别学习的分类/回归模型的问题,定义为有图像条件的掩码生成问题。根据生成学习这个概念,作者利用已有的生成模型在建立的有条件的图像生成框架里面实现了一个生成式语义分割模型。具体的实现是对给定的分割掩码图,在引入的条件网络下,通过两步优化,stage1是学习潜在变量的后验分布,stage2是最小化后验分布和给定输入训练图像与它的分割掩码的潜在变量的先验分布之间的距离。
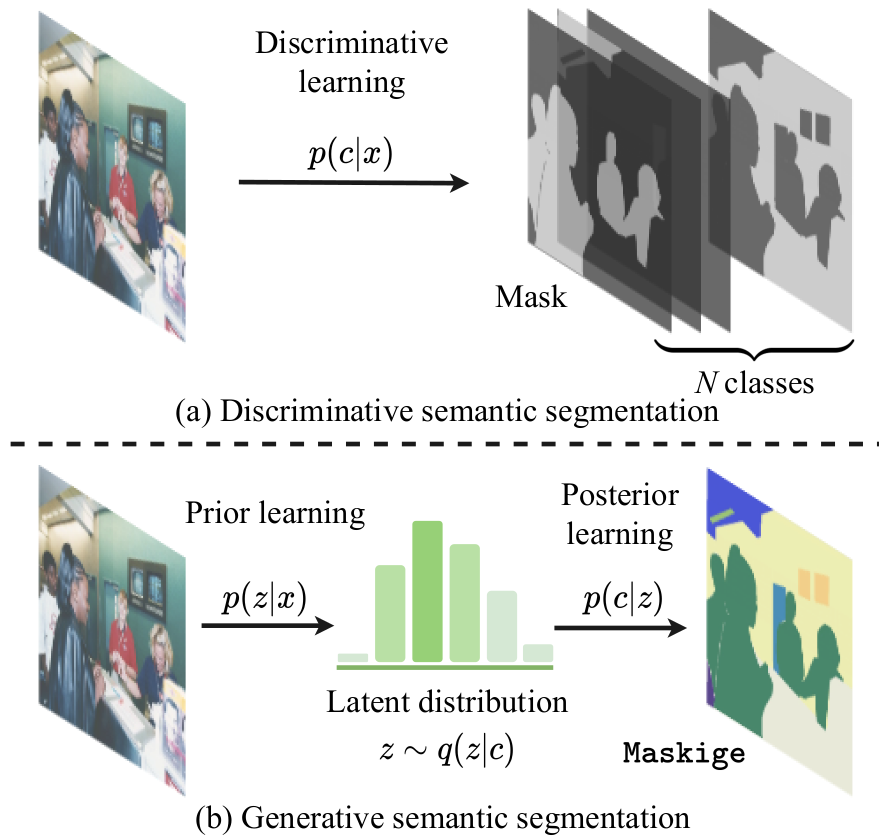
生成模型会通过一个隐变量分布来学习后验分布,通过后验分布来学习数据生成过程。
背景
语义分割
方法的进化,从一开始FCN的提出,通过卷积神经网络去分别每个像素,紧接着方向放在了提升模型的有限感受野,整合多个尺度的,在卷积层的上下文内容,帮助网络学习到更高层次的语义特征。接着来到了注意力机制的时代,将注意力机制放进卷积框架里面;然后随着ViT的出现,更多基于Transformer的方法;以及最近一些使用二分图匹配凸轮的算法来显示语义分割;这些方法都采用的是判别式逐像素的分类学习范式。
图像生成
生成模型通常可以在两个阶段训练过程进行优化,第一个是优化数据的表示,即特征表示,第二个阶段是建立一个概率模型。
在学习数据表示上,VAE通过变分推断重构了自动编码器,VQVAE则是将图像表示学习扩展到离散空间,用于实现一些语言图像的多模态生成。
在概率模型学习上,使用Transformer模型来建模条件和图像之间的组合关系。
视觉感知生成模型
GMMSeg通过用生成高斯混合模型替换判别式分类器,但它其实还是判别式模型;Pix2Seq介绍了序列到序列的任务无关视觉框架,但相关的方法需要从头开始训练模型,产生较大的计算开销。
作者提出了一个称为“maskige”的概念,以RGB图像的形式来表示分割掩膜,从而可以采用已经在大量不同图像上预训练的线程数据表示模型(例如VGVAE)来进行学习,这最终使生成分割模型的训练与传统的判别式模型一样高效。
实现
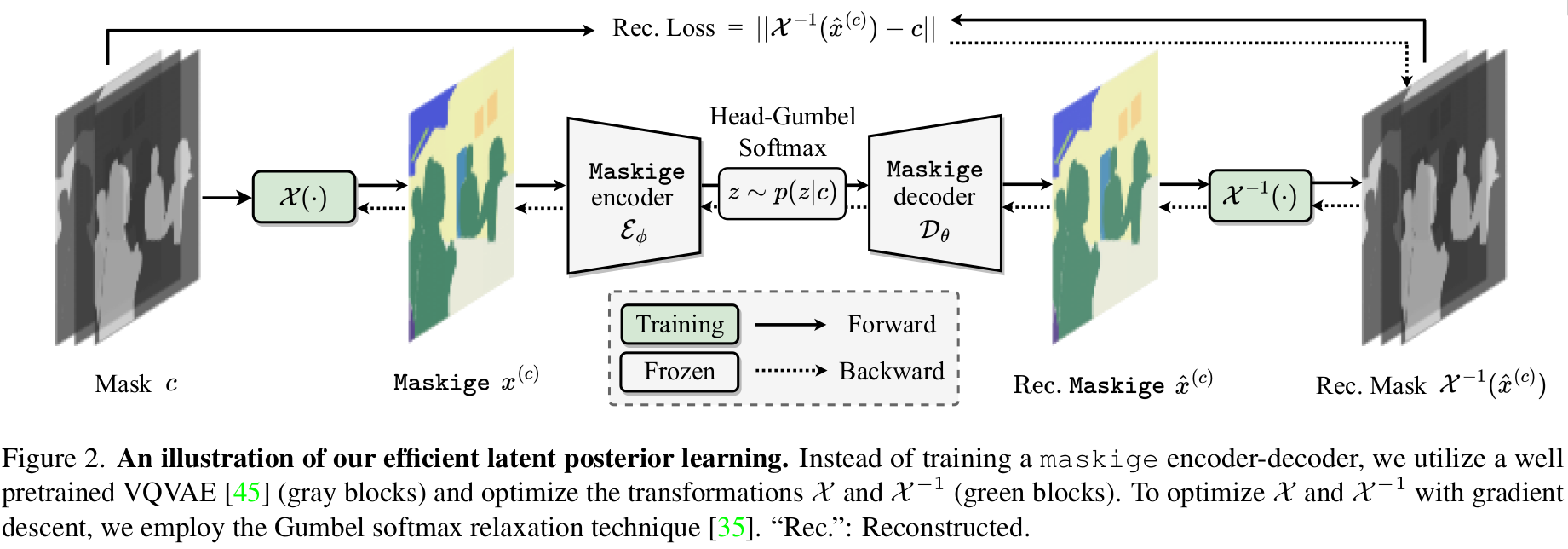
潜在后验学习示意图,直接利用预训练模型VQVAE来做编码器和解码器,而不是直接从头开始训练一个maskige的编码器-解码器;并采用Gumbel softmax relaxation 松弛技术来对$\mathcal{X}^{-1}$和$\mathcal{X}^{1}$两个Transformer进行梯度下降的优化。
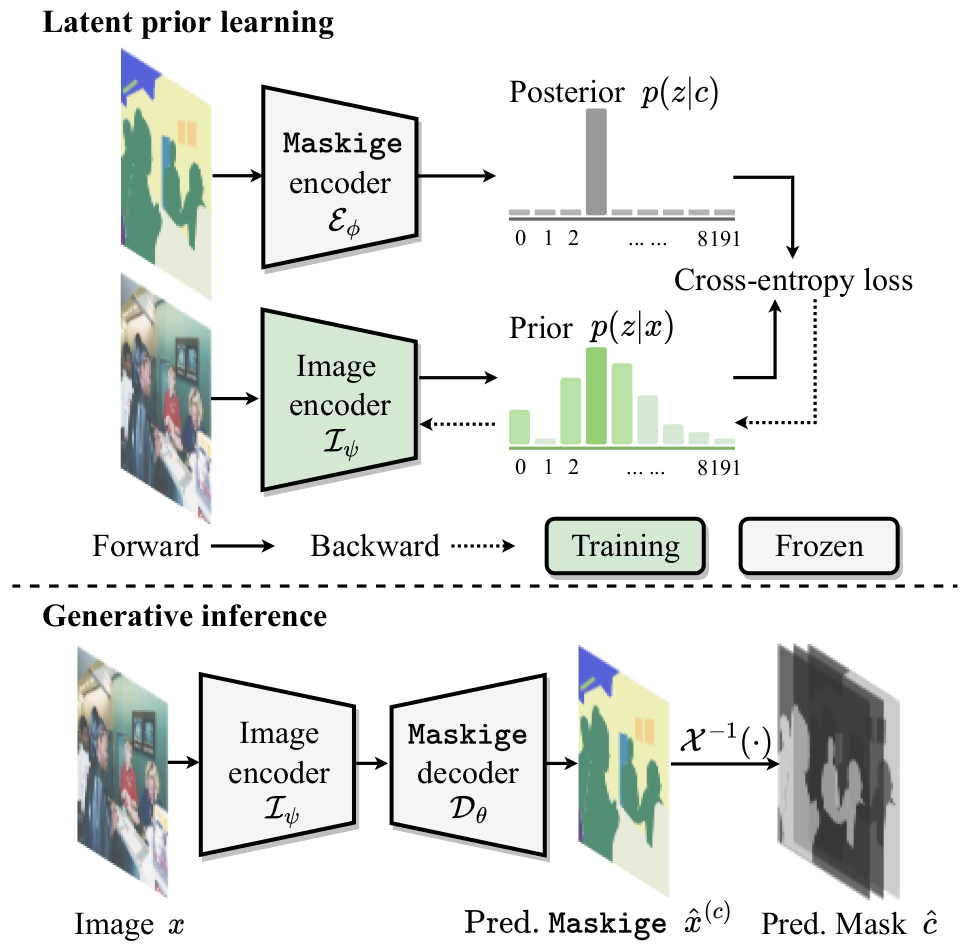
如图所示,上面部分为Latent Posterior Learning的过程,潜在先验学习,下面为Generative inference生成推理的示意图。在训练过程中,对于潜在先验学习,作者优化图像编码器$\mathcal{I}\psi$同时冻结maskige编码器$\mathcal{E}\psi$,目的是最小化隐藏token的先验分布和后验分布之间的差异(文中用交叉熵损失来计算);而在生成阶段,使用图像编码器$\mathcal{I}_\psi$得到的先验分布经过maskige解码器得到maskige和预测掩码。
GSS
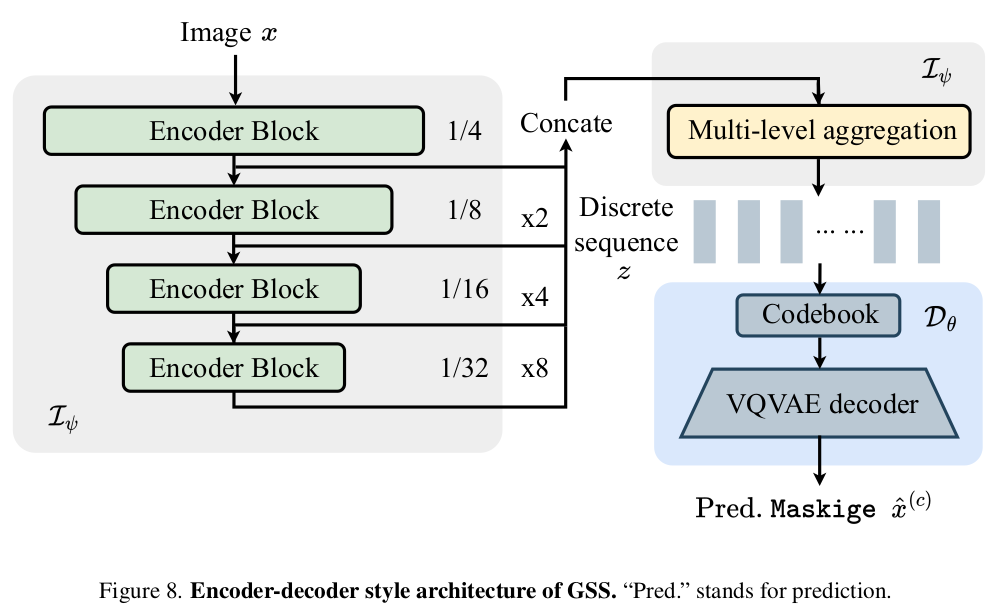
GSS的编码器-解码器框架结构
如图所示,包括三个部分$\mathcal{I}\psi$,$\mathcal{E}\phi$, 和 $\mathcal{D}_\theta$, E和D分别就是VQVAE的编码器和解码器,而I则是由ResNet,Swin Transformer之类的核心网络和一个多级聚合MLA Multi-Level Aggregation 组成。
优化上,与判别式模型的对数似然函数不同,优化ELBO(证据下界,变分下界),无法在端到端的训练达到全局最优化,而之前的优化需要较大的算力,尤其是第一阶段,潜在后验学习,即通过训练VQVAE来重构所需要的分割掩膜;优化的第二阶段,潜在先验学习,学习给定输入图像的潜在令牌的先验分布。
第一阶段
有效的潜在后验学习,在这一部分主要是根据出示的先验概率(均匀分布)学习潜在后验概率分布,而为了优化训练过程,作者提出了一个如图中所示的绿色方块的,$\mathcal{X}$ , 随机变分转换,然后作者发现转换的矩阵可以直接被视作一种RGB图像,每一个类别代表一种特定的颜色,将这个转换后的图片命名为maskige,文中给出了大量的公式推导,为什么maskige可以帮助优化过程,并转变为生成式模型。
将要优化的目标函数转成生成任务之后,就可以直接使用已有的生成与训练模型进行简化,同时在对X优化的时候,会冻结VQVAE里面的参数,不参与训练。
而从mask转换到maskige,作者也提供了线性和非线性的maskige设计;将转换作为线性函数进行优化,要优化的目标函数就可以转化为一个具有显示解的最小二乘问题,这样逆变换就不需要训练,而正变换的零成本训练,可以手动设置线性转换矩阵$\beta$的值,作者建议使用其最大距离假设,以鼓励对
个类别进行编码。(这里有好多数学推导)。
而对于非线性的设计,则是用CNN或者Transformer等模型来表示逆变换。
于是,作者进行了四种对变换的优化设置,
GSS-FF:使用线性函数对变化进行建模,直接使用最小距离假设对转换矩阵进行初始化,所以正变换逆变换都不要训练。 作者在比较的时候使用的是随机的转换矩阵。GSS-FF-R
GSS-FT:正变换使用线性函数,逆变换用三层卷积神经网络表示,所以只有逆变换需要训练。作者在比较的时候,逆变换使用的是单层shifted Window transformer块。GSS-FT-W
GSS-TF:使用线性函数对正变换和逆变换建模,但是对转换矩阵进行训练,以梯度下降的方法,同时优化逆转换矩阵以最小二乘法进行优化。
GSS-TT:用线性函数对正变换建模,但是用非线性函数对逆变换建模,同时,对正逆变换根据梯度下降进行联合训练,而不是之前的分开地训练。
在GSS-TF和GSS-TT里面用到的梯度下降方法,采用的是hard Gumbel-softmax relaxation technique,硬 Gumbel-softmax 松弛技术。
第二阶段
潜在先验学习,这个阶段的主要目的就是训练一个图像编码器,用于接下来最后生成过程中里面的maskige解码器。最小化由潜在先验编码器(图中的image encoder)预测的离散潜在token分布和由VQVAE给出的discrete latent token之间的距离。
而对于标注成本,在现有的判别模型可通过建模每个像素的条件概率,通过在训练期间忽略所有未标记的像素来解决标注高成本的问题;而生成模型无法灵活访问单个像素,为了解决这个问题,作者采用了一种伪标记策略,思想史为每个未标记的像素预测一个标签。在潜在先验学习期间,引入一个辅助头部来标记所有未标记区域。
最后
推理阶段,基于训练好的图像编码器和maskige解码器以及逆变换,输入图片得到最后的预测mask。
实验
在ablation studies里面,作者观察了上面第一阶段,潜在后验学习,优化两个变换的方法,最后是选择了GSS-FF 最高效 和GSS-FT-W 最强, 一个是没有额外的训练消耗,一个是以Transformer建模的逆变换。
在VQVAE的设计上,也比较了不同的结构,作者采用的是DALL.E Style预训练模型。
潜在先验学习上,分析了伪标记和多级聚合 MLA Multi-Level Aggregation(用在图像编码器里面)。
结果
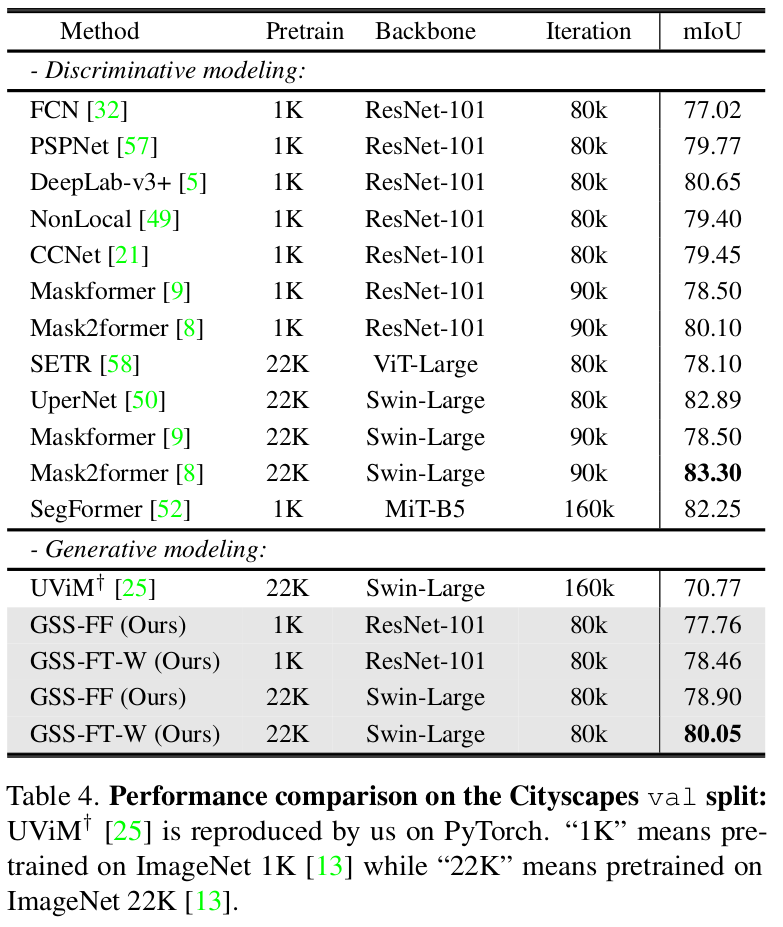
单域
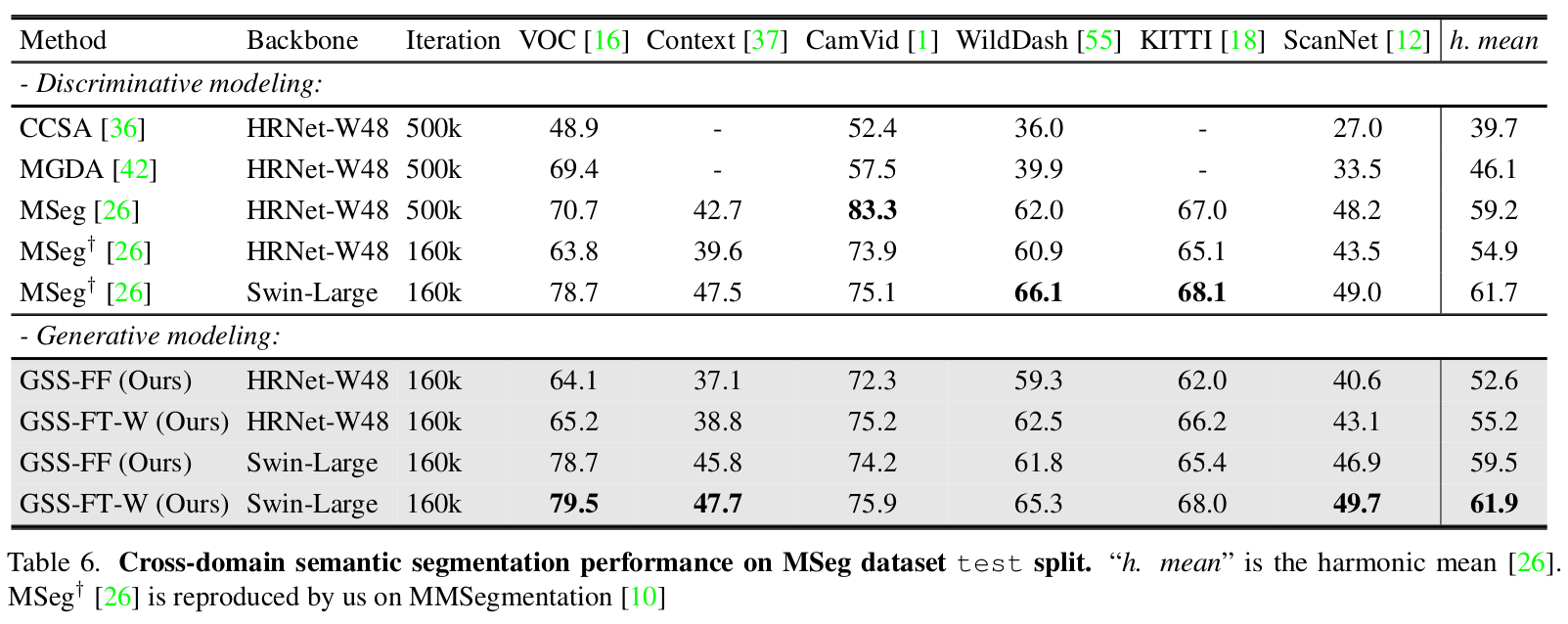
跨域
GitHub
https://github.com/fudan-zvg/GSS
吃力的论文,觉得好多不懂的名词啊,包括像这些概率分布的问题,先验,后验都不记得了,变分推断,ELBO(证据下界)啥的,都不清楚。
在后面的附录里面也给出了相当多关于为什么maskige能够被用来训练,从ELBO损失函数以及潜在后验学习等等的推导。
Last updated