Multi-task SE-Network
Y. Zhang, G. Zhu, L. Wu, S. Kwong, H. Zhang and Y. Zhou, "Multi-Task SE-Network for Image Splicing Localization," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 7, pp.
概述
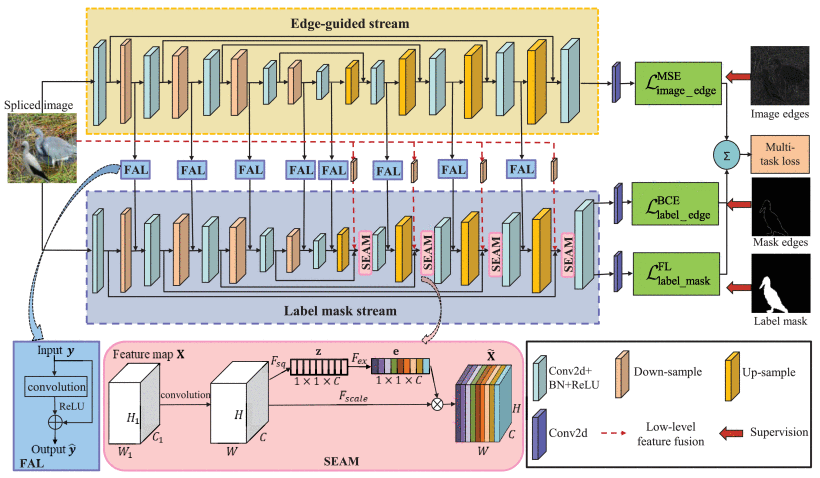
主要的思路就是在特征提取/特征表示的时候,采用的新的元素去提取特征;1. 是使用了image edge(图像边缘??),结合label mask和mask edge;2. 是以往的篡改检测,要不就是只处理了浅层的low-level特征,要不就是只关注了深层的high-level 特征,这次作者把他们fuse了,方法就是使用multi-task learning,同时配以squeeze and excitation attention modules(SEAMs) (挤压和激励,就是卷积的一种方法,就跟ASPP类似那种,有channel-wise squeeze-and-excitation modules, 可能也有layer-wise,spatial-wise;具体就是:Squeeze-and-Excitation Block,可以概括为自注意力机制) 都是为了更好的特征表示;3. 是针对提出的新的使用的image edge对应的loss策略。
None of the existing methods take the edge of images into consideration for splicing localization.
SEAMs
squeeze and excitation 是一个结构单元,它是通过让网络去执行动态的通道特征再校准(recalibrating the discrminative features 校准特征是??),来提高网络的表示能力,具体的过程是:
首先有一个卷积块作为输入,(由于直接将特征图和filter kernel进行卷积得到的特征表示往往本质上是隐性的??和局部的,所以需要重新校准我们的filter来获得全局的特征表示,所以就提出了Squeeze and excitation)
Squeeze: 在feature map上操作,每个通道channel被挤压成一个单一数值,(通过平均池化,average pooling)
dense 层(全连接)之后加上非线性的ReLU,然后输出通道的复杂度按一定比例降低
另一个dense 层接着一个sigmoid(门控),给每个通道一个平滑的门控函数
Excitation: 最后,再两层全连接之后,根据side network(侧面网络??)对卷积块的每个特征图进行加权,这就是“激励”
可以看作是一个feature map,而不是token上的attention,因为注意力机制本质上也是学习一组权值。
具体结构
总体是一个多任务学习的网络结构,分成了两个stream,一部分是edge-guided stream, 另一个是Label Mask Stream,在边缘引导的这一个网络流中,采用的结构是U-Net的结构,encoder负责接收图片,从图片中提取特征;decoder就生成最后的像素水平的预测。在two stream的另外一个stream,标签掩码流,结构是相似的,同时结合了前面的edge的信息,得到最后的mask进行监督学习。
其中,为了将edge stream的特征结合到label mask stream,同一level的feature会透过FALs加到label mask stream上;
第二,为了利用low-level的特征,要融合浅层的low-level feature 和在上采样层里面的high-level feature map;所以就直接从输入的图片分别进行四次8241的下采样,得到low-level feature, 然后再把它们融合到每一次上采样之后的特征图里面去。
第三个就是,这些low-level和high-level的特征融合在一起,是比较粗粒度的,对于拼接检测来说,所以这些融合的特征要经过一个注意力机制来校准,校准之后再去卷积,上采样。
损失函数上,
三个部分,就三个损失函数。
GitHub
https://github.com/YulansZhang/Multi-task-SE-Network-for-Image-Splicing-Localization
Last updated