Harmonizer
Harmonizer: Learning to Perform White-Box Image and Video Harmonization
Zhanghan Ke, Chunyi Sun, Lei Zhu, Ke Xu, and Rynson W H Lau. 2022. Computer Vision – ECCV 2022. Lect Notes Comput Sc (2022), 690–706. DOI:https://doi.org/10.1007/978-3-031-19784-0_40
论文的概念好像很简单,就是我们在从合成图片(composite image)到融合图片(harmonized image)上的方法,从之前的通过使用大规模的autoencoder逐个像素进行融合,到现在论文提出的方法是直接像我们人P图一样,预测出一些滤镜的参数,直接对整个图片进行操作,这样带来的好处就是,处理更快,网络更轻,同时效果还不差。
the main contributions
一个新的框架,Harmonizer,新的网络结构,用来预测对应参数的神经网络以及白盒的滤镜filter,基于神经网络预测得到的参数直接对图片进行操作。
一个层级的回归器,cascade regressor,主要是为了解决学习过滤器的参数不是一个可以同时优化的过程,亮度,高光,很多不同的参数,同时通过使用多头的回归器对每个过滤器单独进行预测,效果不是很好,所以提出了层级的回归器,基于一个级联回归器cascade regressor来解决这个问题,根据前面的过滤器参数的特征来预测每个过滤器参数
一个动态的损失策略,dynamic loss strategy,因为每个filter的损失会累积所有filter的errors,导致回归器对一些filter会有偏差,所有引入这个动态损失策略,就平衡了各个filter的损失,让它更好的学习。
网络设计的想法
两个阶段,因为是白盒,所以就一直以我们人要怎么处理这张合成图片,让它看起来更具有自然性;所以第一个阶段就是,对一些过滤器去调整合适的参数,让前景和背景融合。第二个阶段是根据第一阶段里面使用的过滤器,进一步确定影响最大的过滤器(高光 亮度 对比度...)和他们的参数。
Architecture
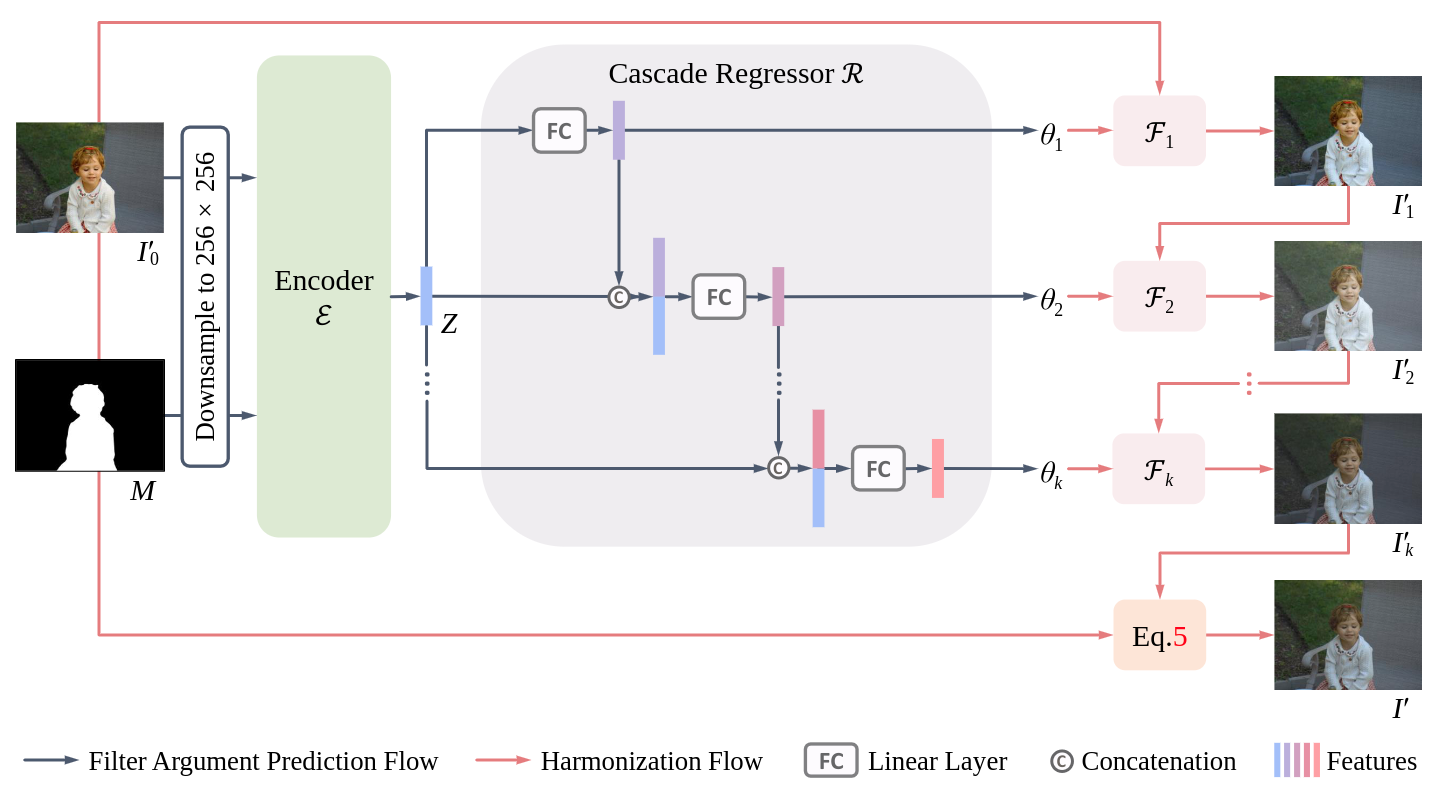
主体就是encoder和regressor的结构,输入一张图片I0′以及它的前景掩码图M, 然后用Encoder ε 和Regessor R 来不断回归,得到k个图像的filter 参数,然后再依次把这些操作放到图片上,得到相应的输出 I′。这里的encoder主要就是用来提取特征的,结构是来自于 EfficientNet-B0,
整个回归的过程,就是首先我们得到了输入图片I0′和前景掩码 M 的特征, Z=ε(I0′,M), 从一开始输入的下采样到 256×256然后得到特征 Z 是 160个channels。接着,通过对特征Z 全局的池化,以及用 R 进行回归,得到最后白盒处理的滤镜参数θ=θ1,...,θk=R(Z), where θi∈[−1,1],i=i,...,k. 有了参数 θ, 就可以得到对应的输出, Ii′=Fi(Ii−1′,θi),i=1,...,k. 最后我们从合成的图片到输出的融合的图片就是, I′=MIk′+(1−M)I0′,然后最后的输出也可以看出来,再次把输入 I0′ 放进去,确保背景的像素不会被改变,改变的只是前景部分,这也是image harmonization 里面比较在意,或者说很重要的一点吗?
Cascade Regressor
这里要回归预测得到k 个filter的参数,视作一个multi-task problem,因为如果只是对每个filter去回归参数,最后的结果不理想,所以需要使用层级的回归器,具体的做法是当我们在对一个参数进行回归的时候,使用前面的filter的参数的特征向量作为条件。从θi=Ri(Z),i=1,...,k. 到
然后就把这6(文章根据自己的实验和经验以及确保程序表现而得出的6个)个filter和之前的,通过encoder得到的特征向量 Z 进行相加,进一步去回归。
动态损失策略:损失函数 Li=M∣∣Ii′−Ii∣∣2=M∣∣Fi(Ii−1′,θi)−Ii∣∣2,i=1,...,k,进一步动态调整为:
其他
实验上就是iHarmon4的数据集, 然后因为在iHarmony4里面的合成图是通过GAN生成的,所以做了一些数据增强,用之前提到的逆向操作。
指标就是常见的MSE Mean Square Error, fMSE foregroud Mean Square Error, PSNR Peak Signal-to-Noise Ration, 那fMSE只考虑前景的原因就是图像融合不会对背景有改变啦。
训练上,用Adam优化器梯度下降,60个epoch,每个batch16张图片,学习率的设置就直接每25个epoch乘以0.1。
最后的评估,一方面就是256256的,但是要看高分辨率的,就很多方法都是在512512上面训练的,所以直接输入2000之类的分辨率不太好,就最后在输出结果的时候上采样(用了一个叫PCM的方法,Polynomial Color Mapping)。
最后的结果就是在一块RTX3090的GPU上训练,SOTA,模型小,速度快,占用内存低。
存在的问题:
(表现上的问题)就是文章里面提到的,对于前景和背景之间有很强的色调差异,以及照明灯光情况差异较大的时候,效果会不好,那文章提到了再加一个filter,之前
没发现有其他问题?感觉问题都是为了结果的更优化。
应用到其他问题上?效果可能不错,用来去生成splicing的数据集。
可以优化的地方?Encoder的结构,是不是有更好的选择,可以提取出合成图和前景mask更好的特征。
GitHub
Last updated