$S^2$CRNet
Spatial-Separated Curve Rendering Network for Efficient and High-Resolution Image Harmonization
介绍
文章提供了一种不需要消耗大量计算资源,保持模型大小在一定范围,能够应用在终端设备上的空间分离曲线渲染网络,对高解析度的图片进行图像融合。
作者首先从前景的遮罩和背景的遮罩的缩略图里面分别提取空间分离的嵌入,然后设计了一个渲染曲线模块,用来学习并结合特定的空间知识,通过使用线性层(主要是一些预训练的图像分类网络,像SqueezeNet,VGG16,把学习到的前景和后景图像的特征结合用颜色曲线来表示),生成前景区域的曲线映射参数;然后再根据学习到的曲线映射参数直接对高解析度的图片进行渲染。
此外作者也针对提出的框架设计了两个模块,一个是用来级联细化 cascaded-CRM(P图往往有很多步,通过级联细化来预测不同的域嵌入),一个是用来语义引导semantic-CRM(会有一个用户引导的语义编码来为每个类别单独学习类别语义的特征嵌入)。
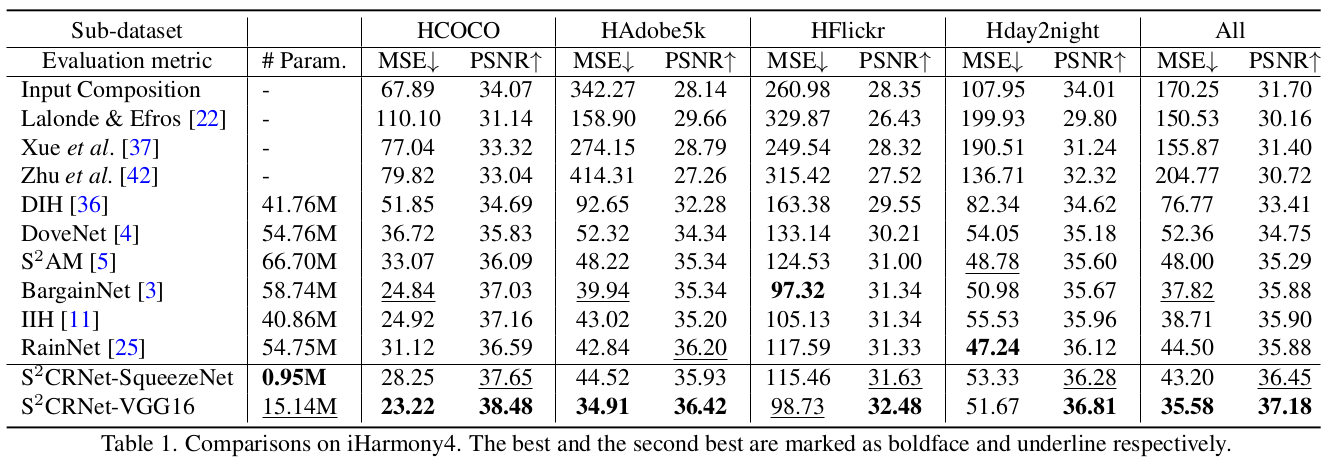
作者在iHarmony4和real-world DIH上进行了测试,达到了SOTA。
当然作者也提到了,他们没有把image harmonization当做一个像素水平的图像到图像的翻译任务,他们也是像Harmonizer一样,把它当做我们人去处理一张图片,要修改哪些参数,不过Harmonizer是选择了一些filter之类的参数,而且说想法来源是看到我们人怎么去处理图像融合的问题,而本文的概念用的是curve,想法来源是因为看到使用像素做图像翻译很吃算力,模型也很大,对高解析度的图片往往很不友好。
框架
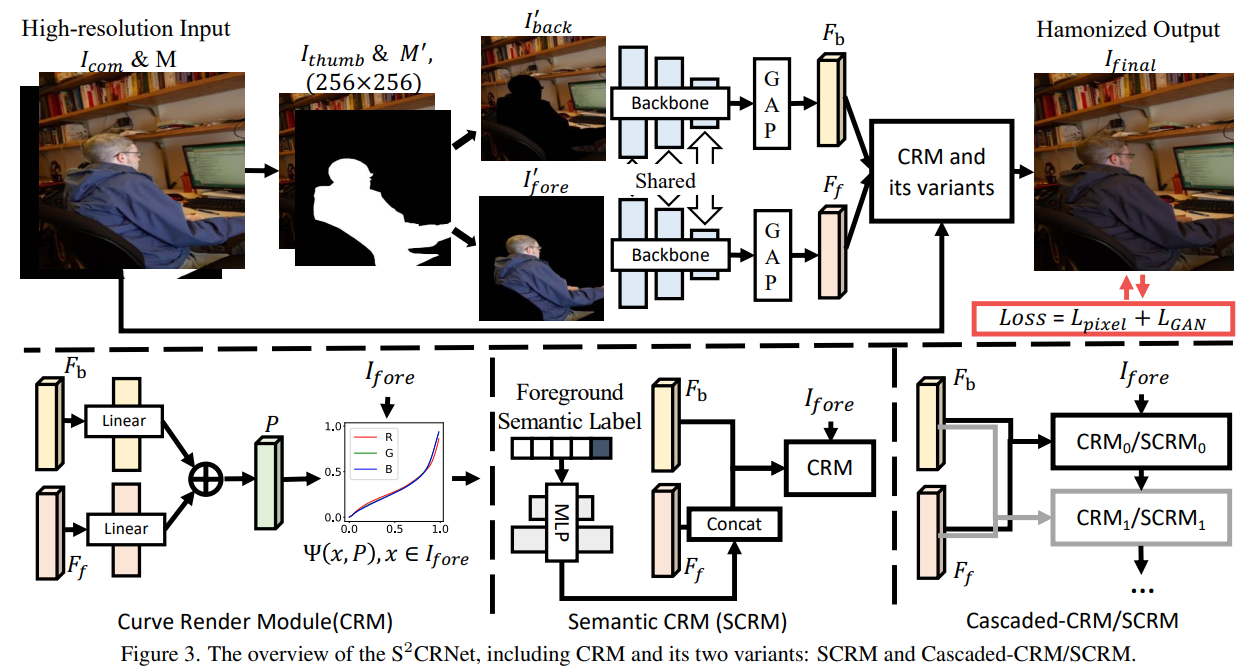
输入一张高解析度的图片,以及它的前景二分掩码图,首先生成它的缩略图,接着进行空间分离的特征编码,通过二分掩码图,将缩略的合成图分成前景和背景,然后用一个共享的编码器分别提取对应的空间分离特征。然后将提取的前景特征和背景特征结合,经过CRM以及它的变体的模块,得到最后的颜色曲线参数。
Curve Rendering Module, 如上图的下面一部分所示,背景和前景的特征,首先经过线性层,作者这里使用的是ReLU激活层,然后将激活后的前景和背景进行channel维度的相加,得到混合特征$P \in R^{3L}$,$L$ 包括RGB三个颜色通道的参数,同时每个颜色通道有$L$ = 64 个参数,(为了平衡复杂度和效果)再将混合了前景和背景的特征经过颜色曲线,并通过近似L级单调的分片线性函数,使其可微。
Semantic CRM, 先给一个类别特征给前景特征,然后再进行相加,再经过CRM,作者这里提供了5种类别来作为语义引导。
Cascaded CRM, 生成多个混合特征,$P_0$, $P_1$, ... 使用多组线性层从相同的全局特征去预测参数P。
Loss, GAN的结构,写了一个判别器,来区分颜色的自然性,生成器去欺骗判别器,判别器努力识别出输入的图片是真是假。
实现
结果
Last updated