MC-LCR
MC-LCR: Multi-modal contrastive classification by locally correlated representations for effective face forgery detection
Gaojian Wang, Qian Jiang, Xin Jin, Wei Li, and Xiaohui Cui. 2021. MC-LCR: Multi-modal contrastive classification by locally correlated representations for effective face forgery detection. Arxiv (2021). DOI:https://doi.org/10.48550/arxiv.2110.03290
通过局部相关表示进行多模态对比分类的人脸篡改检测
概述
论文出发的原因是现阶段人脸篡改检测的系统大多是根据binary mask进行一个全局的监督训练来判断真假,但是目前的篡改技术发展到是进行一些小尺寸的篡改,以及高压缩的后处理和交叉数据集的场景,所以对这种全面的捕获细微和局部的伪造伪影forgery artifacts造成了一些挑战。基于这个原因,作者的做法就是除了具体的人脸的外表特征,还从空间和频域上放大真实的和伪造的人脸之间的隐含的局部差异implicit local discrepancies.。一个shallow style representation block 浅层样式表示块用来浅层特征图的成对相关性 pairwise correlation,把局部的样式信息进行编码去获取更多的判别空间特征。一个*patch-wise amplitude and phase dual attention module** patch维度的复读和相位双重注意力模块,用来获取频域中局部相关的不一致性。(这是基于作者对这些细微的伪造伪影的观察,发现他们可以暴露在patch的相位和幅度频谱中,表现不同的线索)。最后介绍了监督对比损失和交叉熵损失结合的损失函数。
相关工作
Nevertheless, improved synthesis algorithms, small-scale tampering, and high compression settings still pose threats to current detection methods in terms of effectiveness, generalization, and robustness.
也是分成了三类去讨论,空间信息,频域信息(应该就是传统方法,或者。。。),以及结合空间和频域信息的方法。
Although some of the methods mentioned above emphasize local features in the spatial domain, the forgery artifacts in color-space are fragile to compression, thus limiting their robustness in high compression settings.
尽管那些方法都关注到了局部特征,但是篡改的方式/区域往往一压缩,就会丢失掉之前那些空间特征。
What is more, most of the existing frequency-based methods directly transform the entire image into the frequency spectrum for analysis.
such that these methods also suffer from subtle local artifacts.
However, it cannot guarantee generalization only by mining subtle frequency patterns.
大意是其他一些工作都讨论过频域,用了FFT,DCT等等,或者一些相位频谱,的确起到了一些作用,但是他们不能仅仅通过获取这些细微的频域信息就能保证泛化能力。(有点牵强的理由,鲁棒性)。基于以上这些分析,作者得出就是
在空间信息上,除了high-level的语义空间信息,一些潜在的篡改路径,局部模式的相关性编码也值得关注。
在频域信息上,这些小规模的篡改未必会引起频域信息的不同,所以频域信息也要局部化,然后幅度和相位要结合起来利用。
最后也是损失函数,因为是空间和频域两个特征,所以算是多模态,常见的DNN的二分类问题的交叉熵损失容易有过拟合(这是一个nontrival task?? binary cross-entropy loss does not directly encourage wider separation between cross-domain forged faces)。
方法
针对上面三个就是三个contribution,双流的网络结构,空间和频域两个分支,在空间上,用Xception作为骨干网络,SSRB把Xception1-3块提取的特征截断得到浅层的样式特征SSFb1, SSFb2, SSFb3, 这些局部的特征可以用来补充通过Xception最后一个block生成的全局特征,进一步得到最后的空间特征。对于频域信息分支,图片首先转为灰度图,然后分割成pathces,每个patch都独立的进行一次傅里叶变换,也就是patch-wise的DFT,得到每个patch的幅度谱和相位谱。接着幅度和相位分别进行展平,线性投影到对应的嵌入上,这样可以把位置信息进行编码,通过这个embedding layer。然后PA-PDA捕获到幅度和相位里面的异常,生成对应的tokens,再通过一个MLP-Mixer网络和全局平均池化GAP得到最后的相位特征和幅度特征。
SSRB
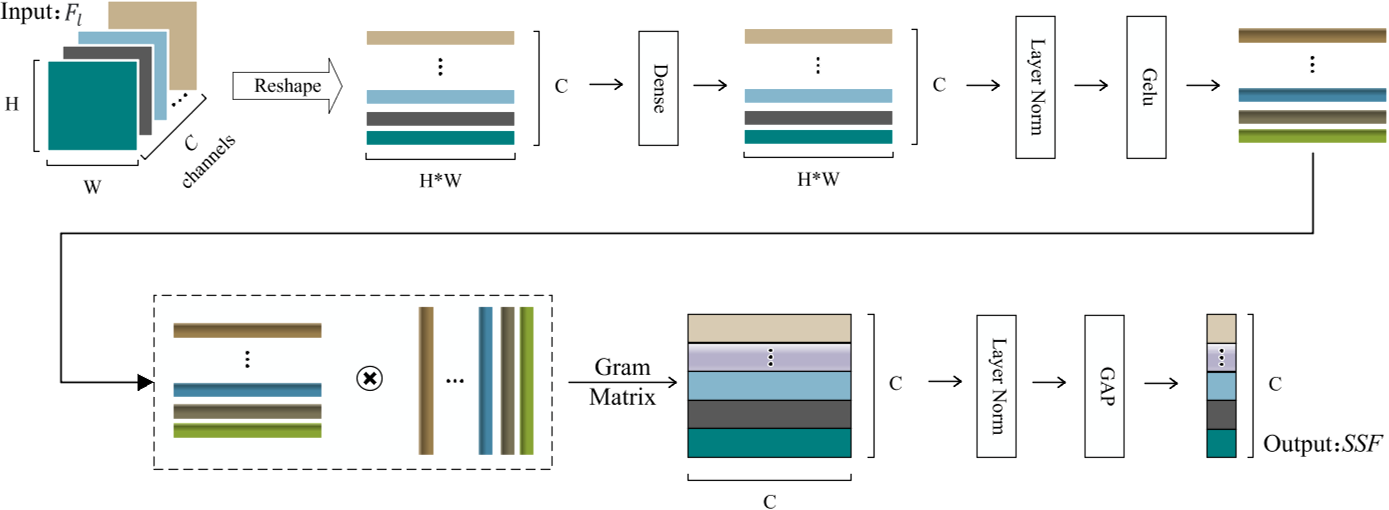
shallow style representation block,用来获取浅层特征,
PA-PDA
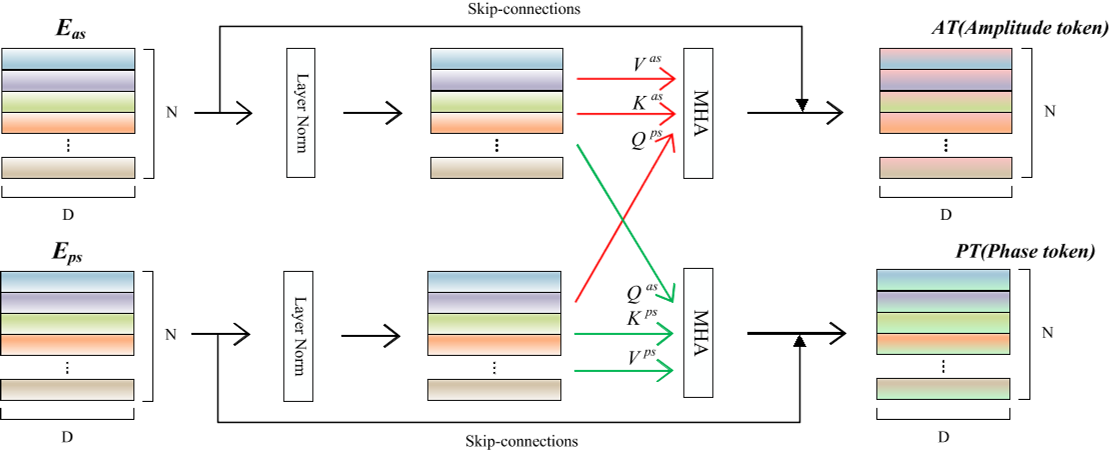
Patchwise amplitude and phase dual attention module,用来捕获幅度和相位中的异常信息,
Loss
Cross Entropy and Supervised Contrastive
实验
数据集
FaceForensics++(FF++): 根据不同的压缩水平有c0(RAW), 轻度压缩c23(HQ),重度压缩c40(LQ), 因为RAW已经基本上检测准确率没什么提高了,用了c23和c40. 总共1000个视频,720个用来训练,140个用来验证,140个用来测试。
Celeb-DF, and DeeperFroensics
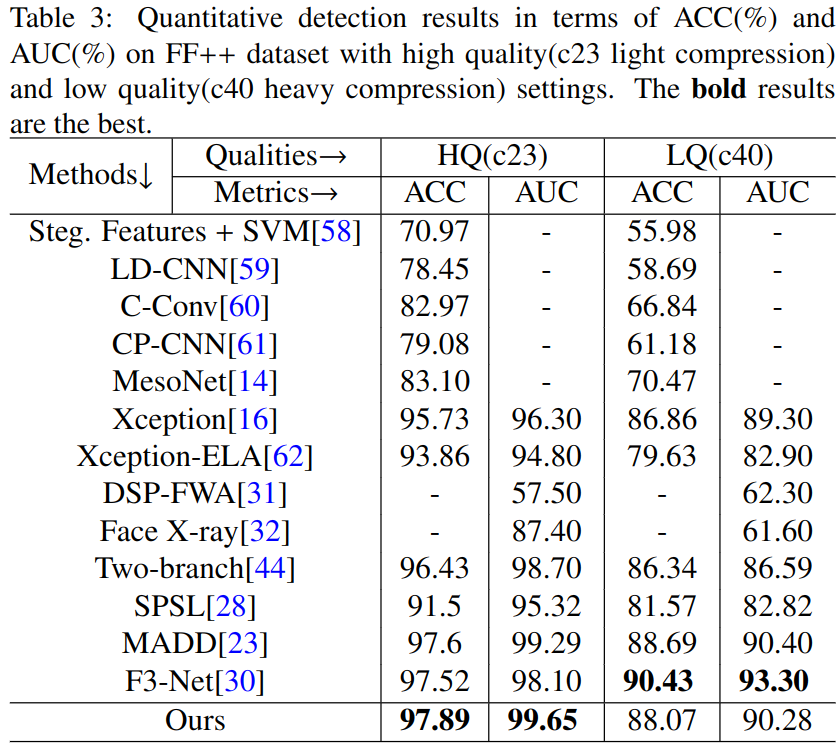
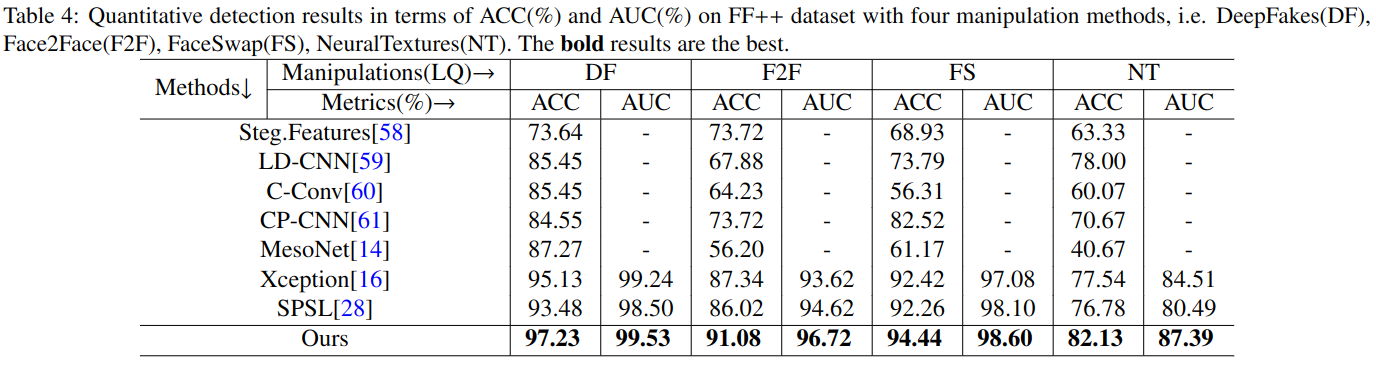
指标
frame-level的ACC(accuracy)和AUC(area under curve of ROC)
具体
对FF执行不同的deep fake方法进行评估,在FF上不同压缩程度的检测评估,评估效率,参数,GFLOPs,MemR+W。
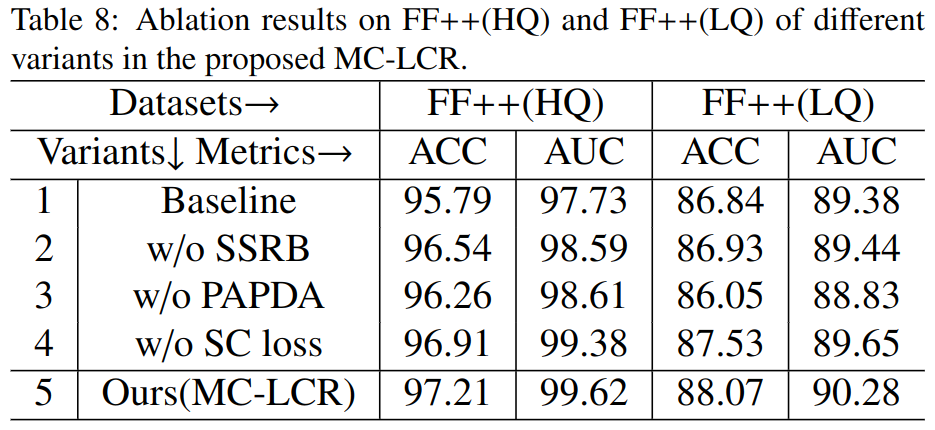
消融研究
就是上面提到的三个方法。还有其他一些实验,例如对backbone的,对于不同数据集的。
总结
文章发表在KBS(ccf-c)上面,其实频域和空间结合的做了好多了,感觉也已经快被做烂了,新颖或者出彩的地方我觉得可能还是得写的出彩。或者结果有明显的的好很多,这个方法最后的结果提升其实不算太高,在FF++数据集上,一些方法的差别是97.52->97.89提高了0.37,甚至在面对严重压缩的时候,自己在论文前面提出压缩是一个问题,但是自己的方法却还没有前人的方法表现的好,这应该是最大的问题了;但由于是期刊,工作量还是很足的。
Last updated