Multi-Scale WaveletTransformer
Multi-Scale Wavelet Transformer for Face Forgery Detection
Liu, J., Wang, J., Zhang, P., Wang, C., Xie, D., and Pu, S. 2022. Multi-Scale Wavelet Transformer for Face Forgery Detection. arXiv.
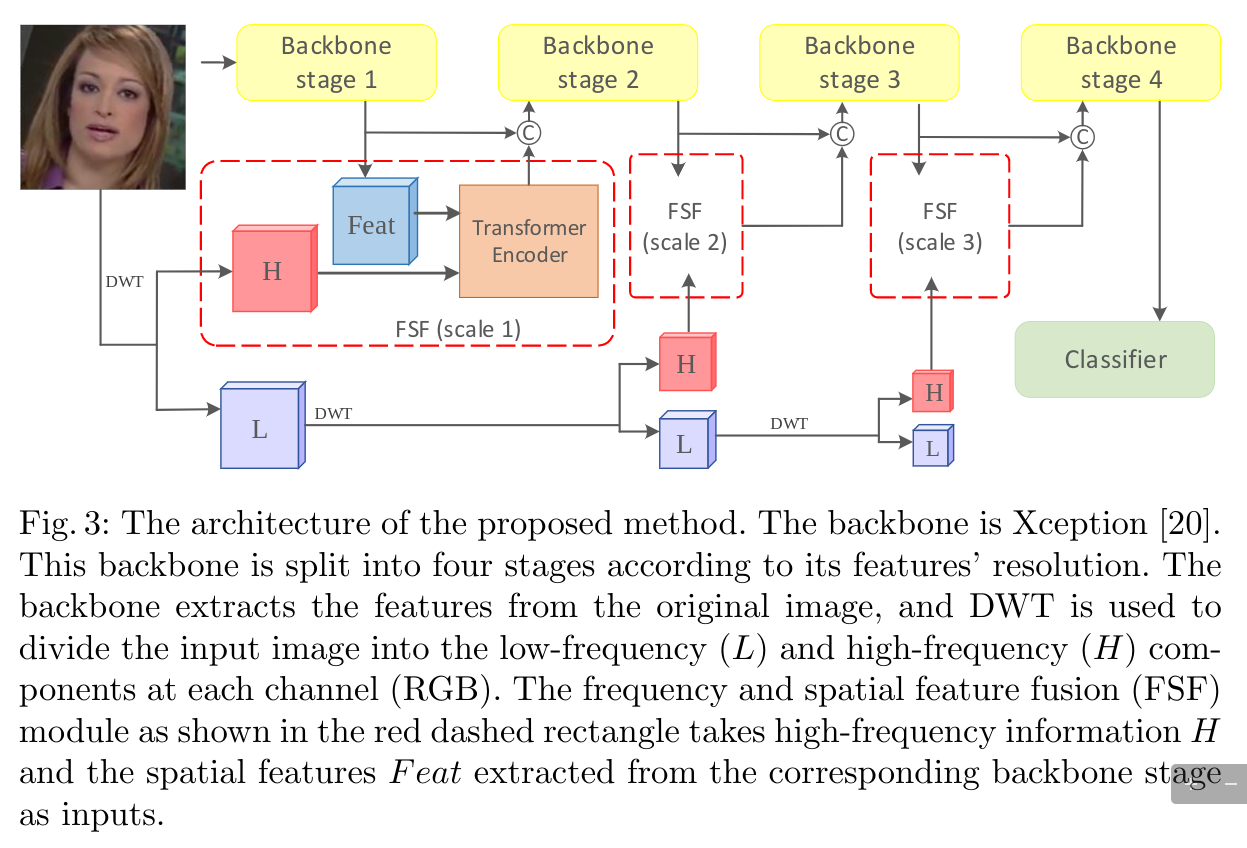
作者的观察:大部分的方法都开始采用Spatial domain和frequency domain来增强泛化能力在不同的数据集下面,作者说DCT,DFT都只能提取1个level的频率,但是他们都只利用到了one level frequency一个级别的频率,仅仅是高频或者低频。作者用了DWT。
所以提出了使用multi-scale wavelet transformer,其实就是multi-spatial和multi-frequency,然后再fuse起来,主要的贡献应该在于是融合两种特征的方法,作者提出了一个frequency-based spatial attention(FSA)用来引导空间特征提取器更多关注篡改路径上,以及cross-modality attention(CMA)用来fuse两种特征。
所谓Spatial and Frequency
一般來說,一張數位影像 就是許許多多的色點 (pixel) 所構成的圖片,而每一個色點都是由紅、綠、 藍(RGB)光的三元色調配出來的,如此便構成了二維的一張影像;我們通常 稱這樣的影像是空間中的影像(Spatial domain)。还有一些hand-crafted feature,像是局部噪声分析,这个和频域特征的区别是?另外,我們有時可以用 一些轉換函數(transformation),來抓住影像的特徵,而這些經過轉換後 的影像,通常就稱為頻率上的影像(Frequency domain)。(因為這類的轉換 函數通常是週期函數)
同时,一般常见的转换函数有,Fourier Transform,Discrete Cosine Transform(DCT), Discrete FourierTransform,Discrete Wavelet Transform(说是就DWT可以获得多级频率);他们的作用往往是用更少的比特获取特征,同时高频信号对人的眼睛不敏感,可以用一些低频信号来表示一些特征而不损失很多信息,同时FFT也能加速卷积操作。
解决的问题是篡改人脸的检测,基本上是一直在优化特征,好像创新是不够多,实验做的很足,有和大约8种方法进行比较,但好像都没有和太多选择同类型用了spatial和frequency的方法去比较,检测有没有,就成了一个二分类问题了,所以,我觉得,
去做定位应该是没有必要,毕竟人脸篡改肯定是修改了一整张脸,把定位的网络,而不是分类的网络做backbone会不会好一点。
值得借鉴的地方,融合两个特征的方法,怎么创新,让他们分别生成一个结果,然后再融合的影响,没必要,或者上GAN,去对抗,用DWT去提取frequency 信息解释起来好像有点儿牵强,频域信息到底怎么用。
Last updated