TBFormer
TBFormer: Two-Branch Transformer for Image Forgery Localization
Liu, Y., Lv, B., Jin, X., Chen, X., & Zhang, X. (2023). TBFormer: Two-Branch Transformer for Image Forgery Localization. In ArXiv: Vol. abs/2302.13004. https://doi.org/10.48550/arXiv.2302.13004

概述
针对图像篡改检测,文章提出的方法是,利用两个特征提取的transformer网络结构,一个负责RGB特征,一个负责噪声特征,两个分支不共享权重;同时提出了一个针对融合这两个分支特征的注意力感知的层次特征融合模块Attention-aware Hierarchical-feature Fusion Module(AHFM),利用位置注意力将来自两个域的特征嵌入到同意的特征域中进行特征表示;最后transformer的decoder,同时加入类别嵌入,category embeddings,用来做特征重建以生成预测掩码。
作者提到目前的一些结合RGB和Noise domain的方法,都是基于CNN的结构设计的;而其他一些用到了transformer的网络结构,像是ObjectFormer一般都不是直接将图片作为输入,而是先用CNN进行了特征提取之后再来进行块嵌入; 以及像是ET则是,虽然使用了多个transformer层来提取特征,但是只从RGB域里面进行提取,同时也构建了一个CNN的decoder。
技术贡献
提出了一个新的完全Transformer类型的网络结构,包含两个特征提取的分支,用来做篡改定位。
提出了一个新的注意力感知层次特征融合模块,用来高效的结合来自两个不同域的分支的特征。
提出了一个Transformer的decoder用来做特征重构来生成预测掩码。
模型
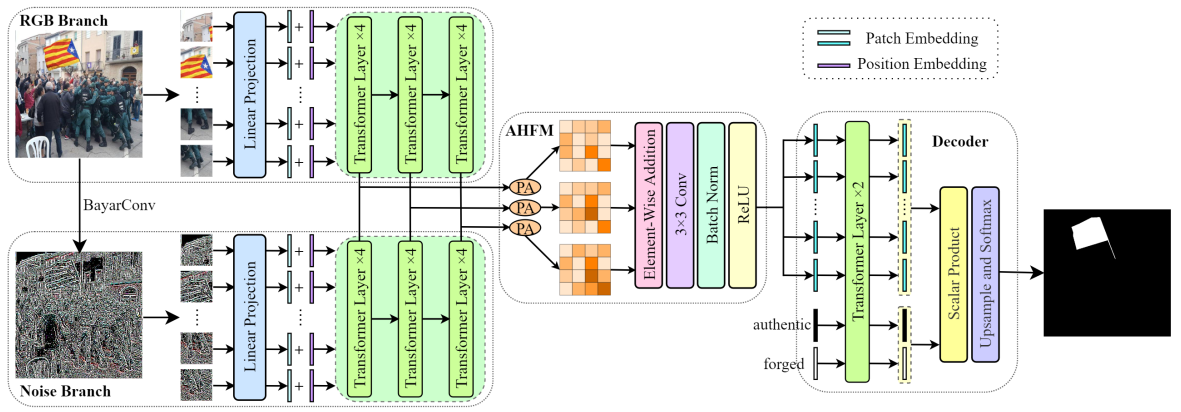
如图所示,一个RGB分支和一个噪声分支,RGB颜色域的图片 $\boldsymbol{I}{c} \in \mathbb{R}^{H \times W \times 3}$ 经过BayarConv (Constrained Convolutional Neural Networks: A New Approach Towards General Purpose Image Manipulation Detection) 网络得到图片的噪声图$\boldsymbol{I}{n} \in \mathbb{R}^{H \times W \times 3}$ ,然后将RGB图片划分为多个16 x 16的patch,$\boldsymbol{X}{c}=\left{\boldsymbol{x}{c}^{(1)}, \boldsymbol{x}{c}^{(2)}, \cdots, \boldsymbol{x}{c}^{(N)}\right}$, where $\boldsymbol{x}{c}^{(i)} \in \mathbb{R}^{16 \times 16 \times 3}$ and $N=H / 16 \times W / 16$ 组成序列,通过线性映射,序列中的每个图片块都会被reshape成1维向量,而一维向量组成的序列就构成了块嵌入序列,patch embedding sequence $\boldsymbol{P}{c}=\left{\boldsymbol{p}{c}^{(1)}, \boldsymbol{p}{c}^{(2)}, \cdots, \boldsymbol{p}{c}^{(N)}\right} \in \mathbb{R}^{N \times L}$;而对应的位置编码则是如图中所示,直接分别加到对应的嵌入序列里面,组成最后的输入序列。$\boldsymbol{E}{c}=\left{\boldsymbol{e}{c}^{(1)}, \boldsymbol{e}{c}^{(2)}, \ldots, \boldsymbol{e}{c}^{(N)}\right} \in \mathbb{R}^{N \times L}$, where $\boldsymbol{e}{c}^{(i)}=\boldsymbol{p}{c}^{(i)}+\text{pos}{c}^{(i)}$
接着将输入序列喂进由12个Transformer层(多头自注意力模块和一个多层感知模块(这不就是CNN?MLP))组成的特征提取器,然后收集第4,8,12层的输出$\boldsymbol{T}{c}^{(4)}, \boldsymbol{T}{c}^{(8)}, \boldsymbol{T}_{c}^{(12)}$;
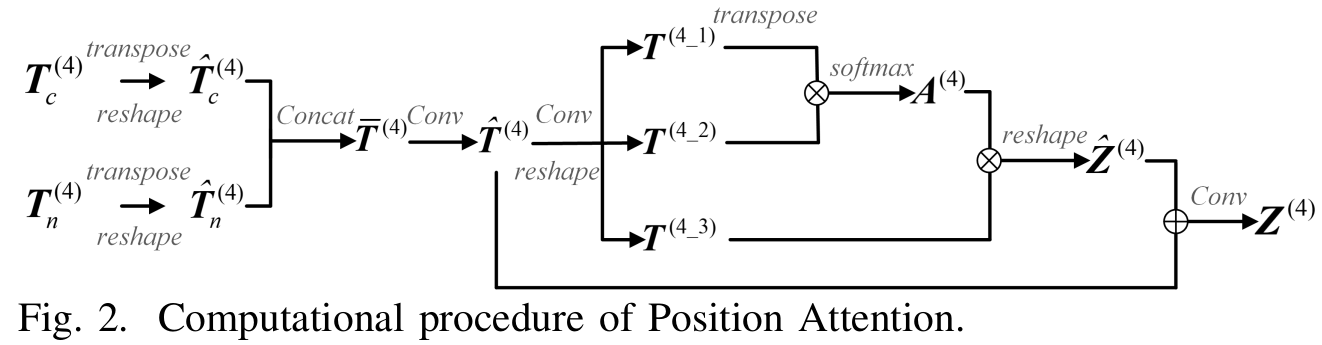
同样的,在噪声分支上,以相同的模块,但是不共享的权重。紧接着来到AHFM模块,进行两个分支的特征的融合。由于两个分支的特征相差较大,所以在注意力感知层次特征模块里面,作者构建了一个位置注意力模块(position attention PA)模块。如下图所示,分别将从特征提取器第4/8/12层得到的特征图,首先经过转置然后reshape成三维向量;接着将两个分支的转置变换后的特征相加(concatenate,以通道维度),再经过卷积,再次经过三个不同卷积核的卷积,得到三个新的特征图,再经过softmax得到位置注意力权重,最后进一步得到融合的特征图。以同样的方式得到第八层,12层,三个融合后的特征图,经过逐个元素的相加,3*3的卷积,批标准化,ReLU激活得encoder阶段最后的融合的特征图。
接着来到了解码阶段,直接当做语义分割的任务来对待,设置两个可学习的类别嵌入(真实的,篡改的)来进一步学习真实的和篡改的特征表示,这两个类别嵌入和融合特征的块嵌入一起输入到解码器的两个Transformer层里面,来得到预测掩码。为了得到融合特征的块嵌入,patch embeddings,首先是reshape,transpose,然后线性映射;这些嵌入和类别嵌入一起输入到Transformer层,经过正则化上采样等操作得到最后的预测掩码。
如上述公式,Z代表encoder的融合特征的嵌入,而S代表类别嵌入,经过proj(线性映射函数)以及L2(正则)的带最后的量化值Y,然后再经过对Y的上采样,得到M 预测掩码。
实验
设置
针对splicing,copy move,inpainting(removal)都制作了大量的数据集,140432张用来训练,7787用来validation,7787用来测试。而在测试集上,用了4个公开的数据集,NIST,CASIA v1.0,IMD20,以及Realistic来进行评估。评价指标上,使用了F1-score,IOU和AUC,当预测的mask二值化时,选择0.5作为门限值。一些实验的细节是,所有输入图片是512x512的,优化器用SGD,多项式衰减学习率策略是$l r=l r_{0}\left(1-\text { iter }{\text {current }} / \text { iter }{\text {total }}\right)^{0.9}$,batchsize是8,训练了15个epoch。
结果
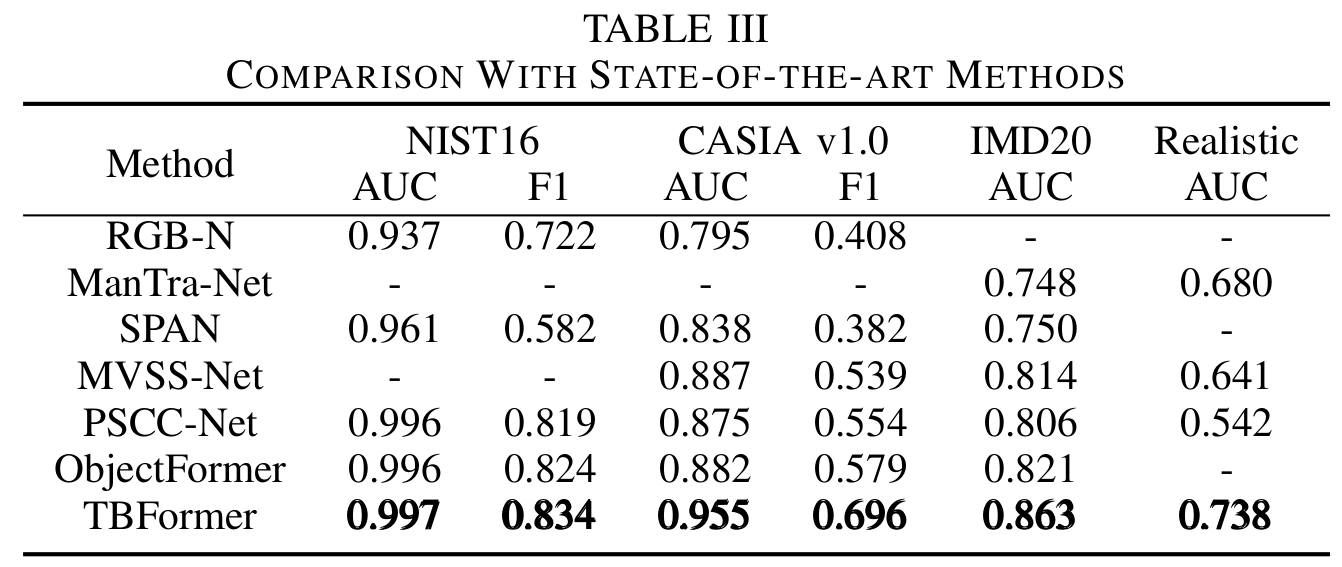
如表格所示,作者进行了和下面几个方法的实验,都达到了比较好的结果。
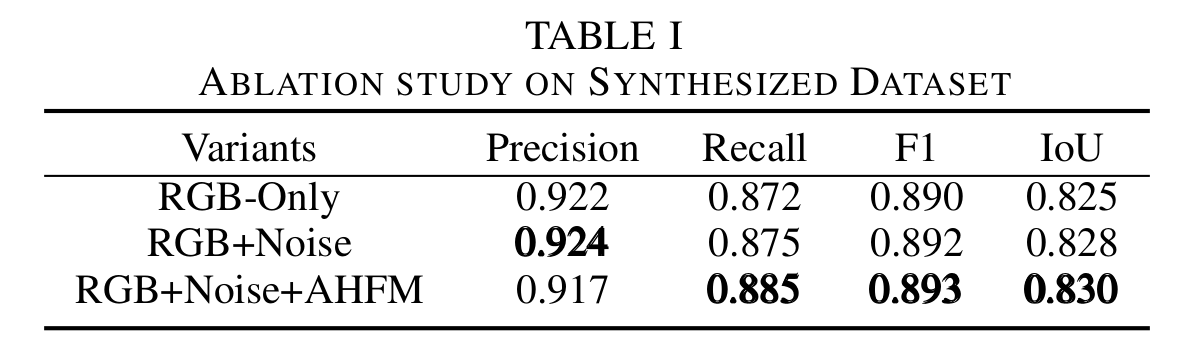
消融研究上,分析了分支的影响,融合模块的影响。
思考
结果是挺好的,但是可能当前在篡改检测里面,这个框架,RGB再堆frequency或者用noise map的概念,已经玩了比较多了,所以文章也花比较少的力气讲为什么要这么结合,而是说我这次的结合和其他人不同,在于我只用用了Transformer,这个理由好像说得过去,又好像不那么强;还重点提到了这个两种特征结合的模块。
那我的问题可能是,noise map对copy move其实是没有用的,以及说整个的frequency;而用noise map仿佛又只考虑到了高频特征,也有些方法是结合高频特征和低频特征,这些。。玄学?
然后是,生成了十几万的训练集,仿佛用来评估的数据集比较少,而且大部分用来评估的数据集仿佛都可以很轻易就被大部分的方法达到90%+,所以在生成训练集的时候,去生成评估用的数据集,会有道理吗?
GitHub
Last updated