SAN and HDU-Net
Image splicing forgery detection by combining synthetic adversarial networks and hybrid dense U-net based on multiple spaces
Y. Wei, J. Ma, Z. Wang, B. Xiao, and W. Zheng, “Image splicing forgery detection by combining synthetic adversarial networks and hybrid dense U-net based on multiple spaces,” Int J Intell Syst, 2022, doi: 10.1002/int.22939.
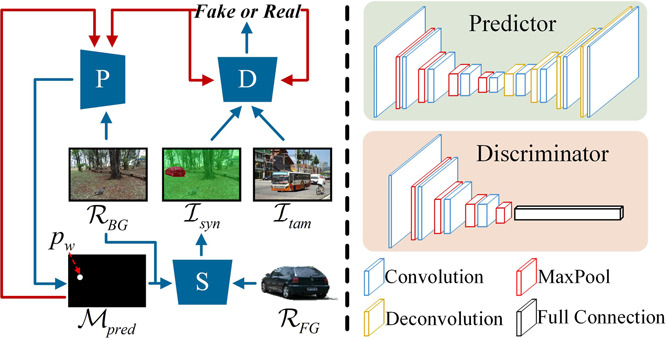
这是SAN的主要结构,蓝色的线表示输入和输出的操作,红色的线表示模型参数的更新,P, S, D, 分别表示predictor, synthesizer, discriminator。
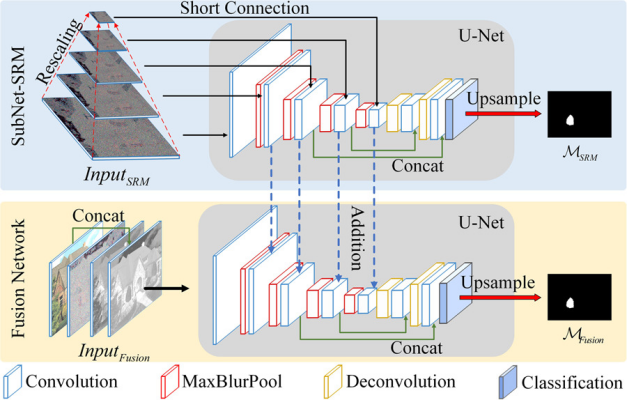
这是HDU的主要结构,提取不同颜色空间的特征进行融合得到的更具有代表性的特征。
总结
文章就是提出了两个方法,一个是SAN, Synthetic Adversarial Network,用来生成ISFD的训练用的数据集,另一个是HDU-Net,运用了不同的色彩范围去提取不同的特征来实现检测定位。一开始作者提出了两个问题,一个是数据集不够,另一个说服力好像不是特别强,说的是拼接用的贡献图和接受图之间的属性差异比较大。所以针对数据集不够,进一步阐述其他生成类数据集的缺点有,拼接的图片往往是随机往donor image上一丢,尽管提出了自己的数据集,还要再fine tune一下才能用,说明自己的数据集就不太好。 关于SAN,作者的方法其实就是一个生成对抗网络,主要包括了一个合成器(生成器),用来把插入的图和背景合成在一起;一个预测网络,用来预测背景图里面可能有篡改的位置,一个判别器,让网络去找到插入的object最适合隐藏的位置。首先就是输入一个accept image(BG),把BG丢到预测网络里去找到最适合隐藏的位置,然后再与输入的insert object合成,合成之后再放到判别器里面与另外一张真实篡改的图片去判断哪张是真/假的。
对于HDU, 主要的就是除了使用RGB color space,还有其他三种特定的颜色空间,包括1. SRM(进行额外的特征提取,获取更多局部噪声的分布),就跟RGB-N一样,也是从30个filter里面选了3个kernel。2. V (YUV,V channel of YUV)and A(LAB) spaces。网络的结构就是分割任务里面的经典encoder decoder结构U-Net,然后也用了别人提出的MaxBlurPooling,还用了目标识别的DenseNet,(所以都是别人的东西就只能发个C),具体的做法就是分成了4个一样的子网络,针对不同的输入(RGB,SRM,V, A),最后再做一个fusion,RGB和SRM关注篡改和没有篡改的属性差异,V A关注篡改区域的边缘信息。
问题
提出的方法生成的数据集其实质量比较差,尽管可以用来训练,但是对高解析度的图片可能都没办法处理,随着网络的发展,解析度越来越高的图片一定是日常,篡改也越来越在意在高解析度上的完美。
SAN里面的predictor是从大量被篡改的图像中学习来模拟图像攻击者的伪造方式,
GitHub
Last updated