SelfDM-PS
Two-Stage Copy-Move Forgery Detection with Self Deep Matching and Proposal SuperGlue
Yaqi Liu, Chao Xia, Xiaobin Zhu, and Shengwei Xu. 2021. Two-Stage Copy-Move Forgery Detection with Self Deep Matching and Proposal SuperGlue. Ieee T Image Process PP, 99 (2021), 1–1. DOI:https://doi.org/10.1109/tip.2021.3132828
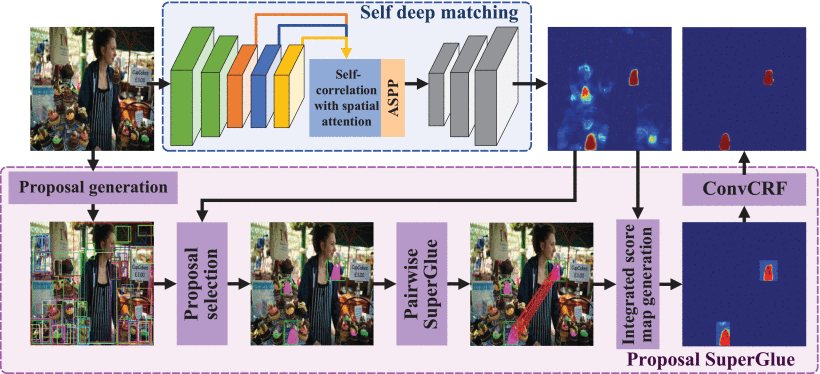
两个阶段,分别是一个端到端的深度匹配,另一个是提出的基于SuperGlue的关键点匹配。
第一个阶段
作者主要就是整合了空洞卷积,跳跃匹配以及空间注意力机制,搭建了一个骨干网络,self deep matching, 来生成backbone socre map, 什么打分矩阵,里面就是各个像素点的可能是篡改区域的可能性。
空洞卷积用来获取更高分辨率的特征图;跳跃匹配可以得到更多层次的信息,multi-hierachical;使用空间注意力机制的自相关模块可以用来获取inherent connections, 前后的连接??,在空间注意力和自相关之间。(他说以前的方法都是只用了VGG16,他们还尝试了好多,包括像ResNet50, 101,)他们认为这个第一阶段的骨干网络就是一个filter,一个过滤,来帮助找到可疑的篡改区域。
但是第一阶段找到的可疑篡改区域可能有些是错误的,false-alarmed, 或者是不完全的,in-complete regions, 所以他们提出了第二阶段,用来移除这些误报,然后修复这些不完全的候选区域。
第二个阶段
在第一个阶段就是用深度学习,找了个图像识别的经典网络,加上了一些特征提取以及匹配中的小方法,像是使用了空洞卷积,然后使用了跳跃匹配,以及在自相关里面使用了空间注意力机制。在第二个阶段,作者同样是在做匹配,只不过第二阶段是基于关键点的匹配,Proposal SuperGlue, 还是将原图输入进去,作者首先是用来一个找候选bounding box的方法(Learing to segement object candidates, Pedro et al,. 2015),一个物体检测的方法??,找到了很多个候选的bounding boxes,然后把这些大量的候选bounding boxes放到一个选择模块里面。这个挑选模块就会淘汰掉很多个之前通过那个物体检测得到的bounding boxes,具体是怎么挑选的,作者利用在第一阶段的得到的打分矩阵来做选择,这样就把两个阶段结合起来了,作者说是在深度匹配和关键点匹配上搭建了一个桥梁。
得到被筛选之后的bounding boxes之后,作者使用SuperPoint来提取关键点,然后使用SuperGlue来做关键点匹配。然后也结合在第一阶段得到的打分矩阵,生成了匹配的接管以及第二阶段的打分矩阵。再通过一个全连接的ConvCRF(Convolutional Conditional Random Field),(18年,用来做语义图像分割人物)
缺点
找bounding box的方式一个个匹配,这样好像容易出现mosaic artifact??就是一块一块的,同时,因为是来自于物体检测里面的方法,所以,对于某些背景的copy move的检测可能并不到位,例如真实的图像是一群鸭子在水面上,然后复制一块水面,粘贴到一支鸭子上,然后网络可能选不出水面这个bounding box。而如果是对于复制一个鸭子再粘贴一个鸭子,可能容易找到bounding box进行特征匹配。(会有这样的问题吗)
Last updated