GSRNet
Generate, Segment, and Refine: Towards Generic Manipulation Segmentation

Peng Zhou, Bor-Chun Chen, Xintong Han, Mahyar Najibi, Abhinav Shrivastava, Ser-Nam Lim, and Larry Davis. 2020. Generate, Segment, and Refine: Towards Generic Manipulation Segmentation. Proc Aaai Conf Artif Intell 34, 07 (2020), 13058–13065. DOI:https://doi.org/10.1609/aaai.v34i07.7007
概述
由于现阶段训练数据不够,打标签也很繁琐,所以从image blending的传统工作上入手,提出了一个生成器,用来生成不同篡改类型的图片,进一步提高泛化能力,同时不断训练让算法更加关注在边界痕迹上,生成更加难以被网络识别的图片,以及一个分割和细化网络用来关注篡改的痕迹,而不是语义内容,来提高识别的能力。
网络
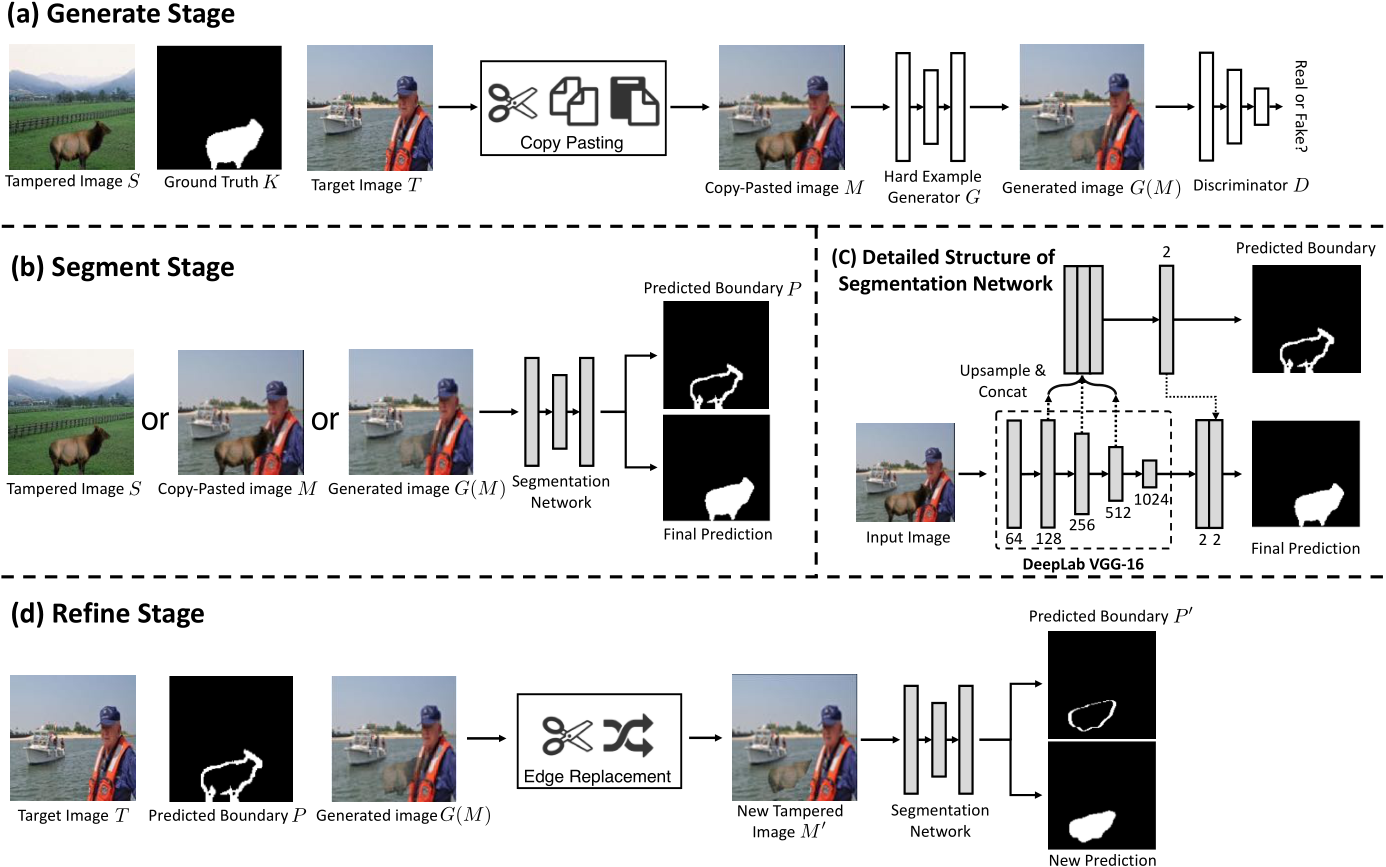
Generator
从篡改的数据集里面找了一些已经篡改的图片S,以及他们的gt mask K 作为输入,同时一些真实的,来自COCO数据集的目标图片 T,简单的生成一张合成图 M,将篡改图片S里面对应的gt作为前景,目标图片T作为背景。同时,和泊松融合类似,他们优化了生成器,提出了一个损失函数用来保证背景不变的同时,强制篡改区域的形状,生成器G将copy pasting的图片M 输入,得到一个困难样本(可能就是比较难以分辨)G(M)。
$\odotd$ 代表逐点乘法,b_i代表的是合成图片的像素, N_{bg}是背景图的所有像素,。
Discriminator
然后用一个判别器来让生成的图片比较真实,判别器是PatchGAN, 进一步优化这个困难样本生成器生成更真实的合成图片, 区分真实图片T 和生成的图片G(K,M)哪个是真是假。
Segmentation
在这个分割网络里,输入一开始的已经篡改的图片S, 或者合成的图片M, 或者经过生成对抗网络得到的G(M),网络要学习分割边界痕迹,得到最后的预测边界,再填充分割后边界的内部,得到最后的预测。分割网络使用DeepLab VGG-16,将池化到128 256 512的低层次的特征连接起来预测边界的痕迹,然后在用边界特征经过连接回分割网络进行最后的预测(填充)。
Refinement
在细化阶段,输入一开始的目标真实图片T, 经过分割网络得到的预测的边界特征P,以及经过生成对抗网络得到的G(M),然后经过一个边缘的替换,将分割阶段得到的新的预测边界替换为原始的真实区域,得到一张新的篡改图片M', 然后再把这张新的图片丢到分割网络里面进行预测。主要就是为了让训练的时候关注边界。
实验
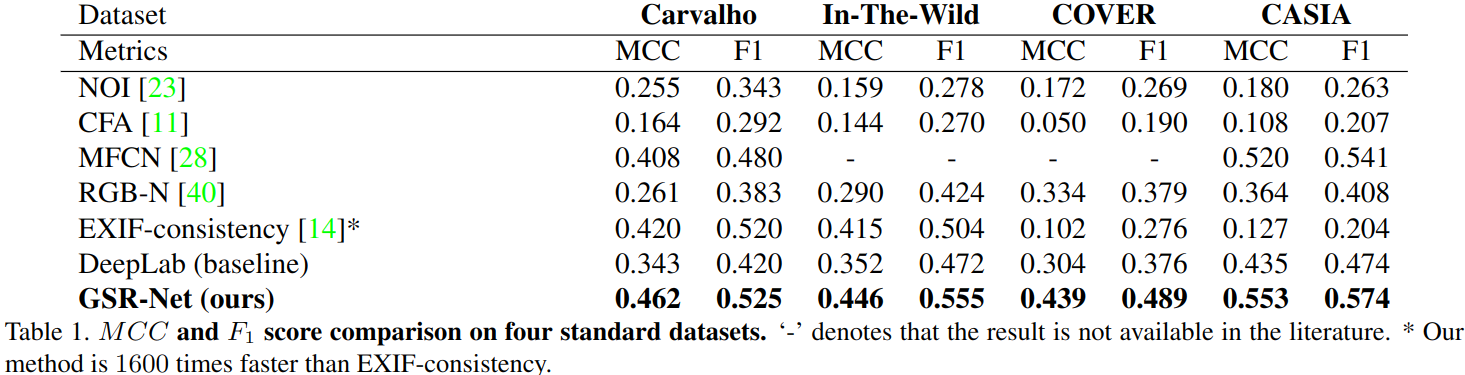
四个公共的数据集,分别是In-The-Wild, COVER, CASIA, Carvalho.
在一块泰坦P6000上面跑的,输入到GAN里面的图片都是
256 * 256, 生成器是基于U-net,判别器是PatchGAN,分割网络是加了batch normalization的deep lab VGG-16,同时网络在是在ImageNet的预训练权重上微调,但是生成网络是从头开始训练。只有分割网络是用来推理的,分割网络分支的结果也是最终的结果。
因为batch size比较小,用了实例归一化,BN注重每个batch的数据分布一致,这是因为判别模型中结果取决于数据整体分布,但是图像风格化中,生成结果主要依赖于某个图像实例,所以是对图像的HW做归一化,加速模型收敛,保持每个图像实例之间的独立。??
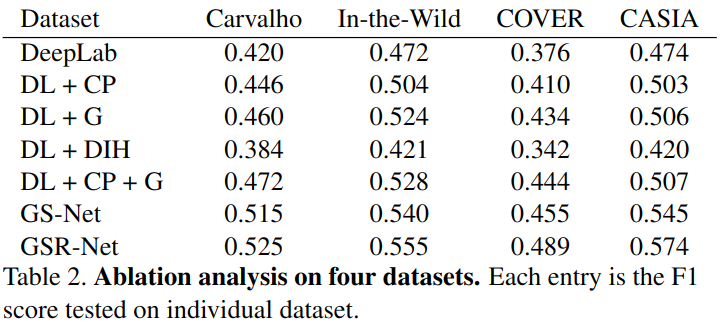
消融研究上,就是考虑CP(copy-paste),CP和G(用了copy-paste和生成器生成),还有用image harmonzation(DIH),以及不包括refine net,(DL+CP+G)没有学习篡改痕迹,所以泛化能力很有限。
鲁棒性上,加了JPEG压缩和图像缩放的攻击。
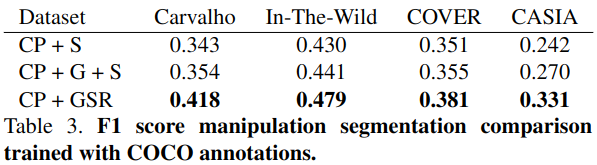
还做了个研究是在分割网络那里一开始的输入,为什么要输入三种,又有单纯合成的,又有网络合成的。
结果
GitHub
TensorFlow: https://github.com/pengzhou1108/GSRNet
Last updated