HT / D-HT
Image Harmonization with Transformer
Zonghui Guo, Dongsheng Guo, Haiyong Zheng, Zhaorui Gu, Bing Zheng, and Junyu Dong. 2021. Image Harmonization with Transformer. 2021 Ieee Cvf Int Conf Comput Vis Iccv 00, (2021), 14850–14859. DOI:https://doi.org/10.1109/iccv48922.2021.01460
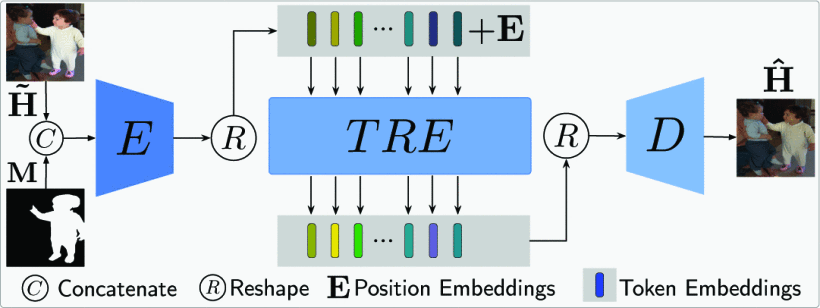
encoder用来获取合成图片的上下文信息,decoder用来重建融合的新的图片,所以也就是两个阶段,首先就是让来自前景和背景的两张不一样的图片可以在颜色等参数上尽量达到一致,第二步就是重建图片,让它符合语义。用CNN的话,他有一个特点,是CNN的局部连接,这就导致了在学习前景和背景的一致性的时候,CNN只能学到前景周围一点像素的内容,而不能看到更全局的内容;虽然采用U-Net的结果,被证实可以解决这一问题,但是在encoder到decoder的skip connection 的时候,也就是第二阶段,也会出现不和谐,这也是skip connection的副作用。
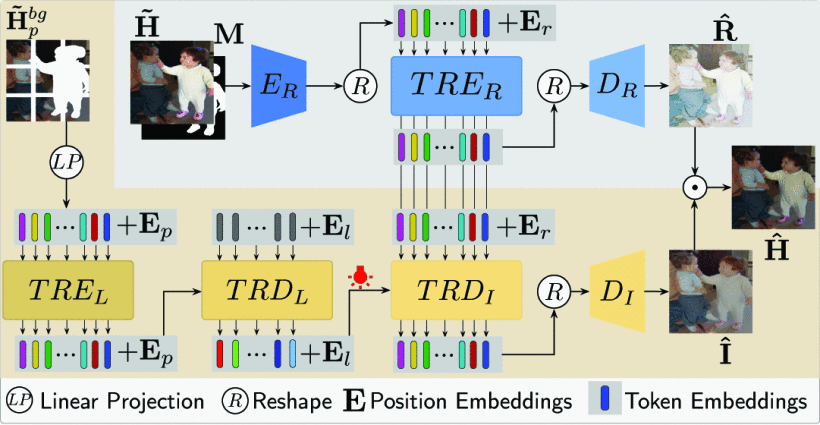
Harmonization Transformer
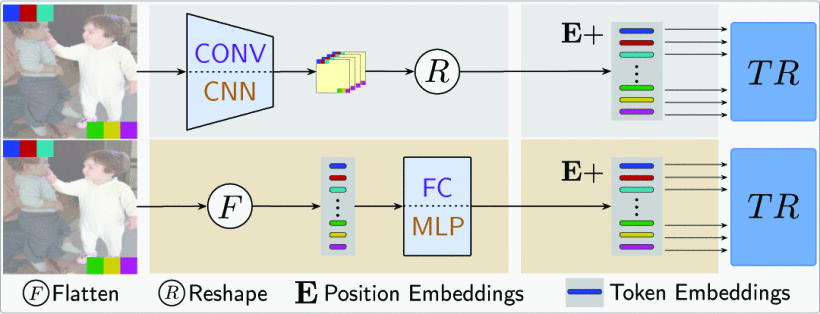
使用transformer那就是注意力机制,一个编码器,一个解码器,在编码器阶段,我们要把输入的图片转成跟NLP里面文本一样的token形式(image patches)和他们的embeddings,具体的token number和embedding type,一般就是看自己设置的stride来选择token number是多少,那么embedding type一般就是线性的,FCN,CNN;那么非线性的就有CNN, MLP之类的。TRE一般就是用来获取一些输入的自联系,使用自注意力机制,self-relations,解码器则是更多的交叉注意力机制来获取输入和解码器的输出之间的cross relations。
Disentangled Harmonization Transformer
解构的HT,就是把图片的光照illumination 和 反射 reflectance 分开考虑,作为两个pathway进行处理,先去用transformer生成伪反射的图片,再生成伪光照的图片,然后再进行融合。作者是基于固有图片的属性以及Retinex理论所产生的这样的双分支,解构的transformer的想法。
伪反射
Last updated